제가 쿠버네티스에서 가장 중요하게 생각하는 부분입니다.
바로 Pod LifeCycle에 대해 알아보도록 하겠습니다.
Kubernetes에서 Pod Lifecycle을 직접 관리해주어야 어플리케이션의 배포나,
HPA 혹은 부하가 넘칠 때, 파드를 죽게 만들지 않고 서비스를 운영할 수 있습니다.
이러한 부분들이 제대로 설정되지 않을 경우 Zombie 파드들이 생길 수 있고 서비스장애로 이어질 수 있습니다.
Pod LifeCycle에 대해서는 참고하기 좋은 블로그들이 아래와 같이 있습니다.
개인적으로는 카카오의 글은 꼭 읽어보시기를 권유드립니다.
https://blog.risingstack.com/graceful-shutdown-node-js-kubernetes/
Graceful shutdown with Node.js and Kubernetes | @RisingStack
Learn what graceful shutdown is, what are the main benefits of it, and how can you achieve it with a Node.js application running on Kubernetess.
blog.risingstack.com
https://dzone.com/articles/configuring-graceful-shutdown-readiness-and-livene
Configuring Graceful-Shutdown, Readiness and Liveness Probe in Spring Boot 2.3.0 - DZone Java
In this tutorial, you will learn about some of the new features of Spring Boot 2.3.0 and learn how to configure Graceful Shutdown.
dzone.com
tech.kakao.com/2018/12/24/kubernetes-deploy/
kubernetes를 이용한 서비스 무중단 배포
Kubernetes는 컨테이너 오케스트레이션 영역에서 거의 표준으로 자리 잡은 오픈소스 시스템입니다. kubernetes를 사용하게 되면 여러대의 노드를 하나의 클러스터로 묶어서 사용가능하게 됩니다. 클�
tech.kakao.com
위의 글 들을 참고하시면 왜 필요한지 어떻게 구성하는지에 대해서 쉽게 알 수 있습니다.
제가 이해한 바로 정리하여 설명해보도록 하겠습니다.
Pod Lifecycle에 대해서는 먼저 Readiness Probe와 Liveness Probe를 통해 제어를 하게 됩니다.
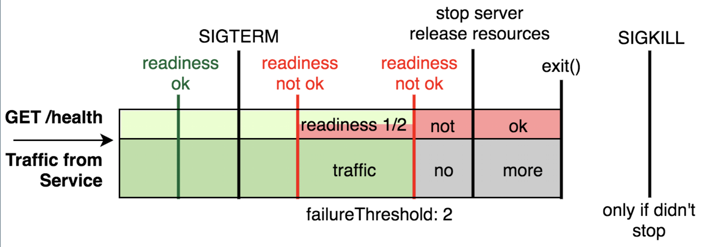
일정 트래픽이상 들어오면 Readness는 해당 파드에 더 이상 트래픽을 부여하지 않아 안정된 서비스를 하게끔 만듭니다.
하지만, Undertow와 같은 WAS들은 Connection을 계속 맺고 있기 때문에, 트래픽이 계속해서 들어올 수 있으며,
이는 Readness와 같은 세팅을 하여 트래픽을 차단하게 하더라도 파드가 죽게되는 현상이 발생할 수 있습니다.
따라서 개발자는 Readness와 Liveness를 고려하여 개발해야하며, yaml 작성도 할 수 있어야 합니다.
쿠버네티스가 Pod Lifecycle을 관리하는 옵션을 기준으로 파드가 시작될 때, 종료될 때를 정리해봤습니다.
먼저, Pod가 시작되는 부분을 보도록 하겠습니다.

도커가 실제로 컨테이너를 띄우면 Node에 있던 kubelet이 이를 watch하고 있다가,
deployment.yaml에 정의된 (정의 하였다면) postStart를 통해 명령어를 수행합니다.
만약 컨테이너에 기본적으로 꼭 올라와야 하는 파일이나 이런 부분들이 있다면,
해당 파일의 경로를 체크해본 다던지 등을 적을 수 있겠습니다.
따라서 실제 서비스가 구동되기 전에 컨테이너에 필요한 옵션을 체크해 볼 수 있습니다.
기본적으로 몇번 실패할때까지 시도할 것인지의 옵션인 failureThreshold
이를 몇초를 주기를 잡고 시도할 것인지 periodSeconds를 통해 세팅하게 됩니다.
postStart 부분이 실패하게 되면 컨테이너의 기초 구성이 제대로 되지 않은 것이므로 종료하게 됩니다.
그리고 RestartPolicy에 의해 컨테이너를 재구동하게 됩니다.
만약 이 부분이 제대로 성공한다면, ReadinessProbe와 LivenessProbe를 체크하게 됩니다.
역시 같은 구조로 failureThreshold 와 periodSeconds를 가지고 체크하게 됩니다.
만약 was의 구동시간이 60초 정도 걸리는데 initialDelaySeconds + (failureThreshold * periodSeconds)가 60초 보다 적다면
Kubernetes는 파드가 제대로 서비스할 준비가 되어있지 않다고 판단하여
Pod의 IP를 서비스에서 떼서 서비스가 되지 않도록 만들고, 컨테이너를 다시 시작시키게 됩니다.
이러한 부분이 계속해서 반복된다면 Liveness Probe의 실패로 계속해서 재구동하다가 새로운 파드를 아에 띄우게되면서
재구동을 무한으로 하는 파드가 Terminating 상태로 계속해서 찍힐 수 있기 때문에 쿠버네티스 자체가 마비되는 Zombie파드 덩어리가 되어버릴 수 있습니다. (경험담)
따라서 시작될 때, WAS의 구동시간이나,
주기적으로 부하에 대해서 체크하여 Readiness Probe와 Liveness Probe를 세팅하는 것이 중요합니다.
그럼 종료또한 잘 시켜야 하기 때문에
이제, 파드가 종료될 때를 알아보도록 하겠습니다.
아래와 같은 절차를 거쳐서 Graceful하게 종료할 수 있습니다.

저는 Spring 공화국인 저희 나라에 맞게 스프링 2.3부터 공식적으로 지원하는 형태를 가지고 알아보도록 하겠습니다.
Pod를 종료할 때는 먼저 preStop 옵션을 Deployment에서 선언할 수 있습니다.
이 전에 Pod가 제대로 종료되지 않을 수 있기 때문에 terminationGracePeriodSeconds를 통해 시간제한을 줄 수 있습니다.
해당 시간이 지나면 파드를 강제종료하게 됩니다.
preStop에서 Readiness Probe의 상태를 Change할 수 있는 API를 콜하게 구성하신 후, 이를 호출하게 하여
더 이상 트래픽이 들어가지 않게 하여 기존 트래픽을 모두 소화할 수 있게 구성하여 주시는 것이 좋습니다.
그렇게 되면 Pod Status가 Terminating으로 변하면서 Spring boot에 SIGTERM을 전달하게 됩니다.
Spring Boot에서 설정한 옵션에서 먼저 timeout-per-shutdown-phase를 가지고 WAS 자체에서 해당 시간이 지나면
WAS가 강제종료되는 옵션을 설정하여 종료할 수 있습니다.
그렇지 않으면 graceful 옵션을 체크하여 상태를 체크한 후 정상종료하게 됩니다.
아래는 스프링 부트에서 Liveness를 Fail하게 만들고, Thershold를 3번으로 설정한 예입니다.

Threshold 3 번을 지나자마자 postStop인 Readiness Probe -> Refuse를 콜하고
SIGTERM이 들어와 서비스가 Graceful Shutdown을 수행하는 모습을 볼 수 있습니다.
해당 WAS는 현재 프로젝트에서 데모로 제가 구축한 부분이어서 연관이 없는 소스로 다시 예시를 개발하여,
구체적인 세팅과 예시를 올릴 예정입니다.
Pod LifeCycle에 대하여 그 개념에 대해 흐름을 알아봤습니다.
조만간 다음 포스트를 작성하며, 구체적인 소스와 예시를 올릴 수 있도록 해보겠습니다.
'EKS > Kubernetes Intro' 카테고리의 다른 글
| Kubernetes - LimitRange (0) | 2020.11.06 |
|---|---|
| Kubernetes - Spring Boot & PodLifeCycle - 1. Source Code (0) | 2020.10.26 |
| Kubernetes - Affinity & NodeSelector 사용하기 (0) | 2020.09.04 |
| Kubernetes - ConfigMap & Secret / Spring Boot 연동 (2) | 2020.07.31 |


